Results
Metrics
- Force Profile Accuracy (FPAcc): Measures how closely the predicted force profile \( \hat{x}_f \) matches the ground truth \( x_f \) using Mean Squared Error (MSE). $$ \text{FPAcc} = \text{MSE}(\hat{x}_f, x_f) $$
- Force Direction Accuracy (FDAcc): Evaluates directional alignment between predicted impulse \( \hat{J}(T) \) and ground truth impulse \( J(T) \) using cosine similarity. $$ \text{FDAcc} = \frac{\hat{J}(T) \cdot J(T)}{||\hat{J}(T)|| \cdot ||J(T)||} $$
- Modifier Similarity (ModSim): Cosine similarity between the predicted modifier \( \hat{w}_m \) and the ground truth \( w_m \) using SBERT embeddings \( E \). $$ \text{ModSim} = \frac{E(\hat{w}_m) \cdot E(w_m)}{||E(\hat{w}_m)|| \cdot ||E(w_m)||} $$
- Direction Similarity (DirSim): Cosine similarity between predicted direction words \( \hat{w}_d \) and ground truth \( w_d \). $$ \text{DirSim} = \frac{E(\hat{w}_d) \cdot E(w_d)}{||E(\hat{w}_d)|| \cdot ||E(w_d)||} $$
- Full Phrase Similarity (PhraseSim): Average of \( \text{ModSim} \) and \( \text{DirSim} \). $$ \text{PhraseSim} = \frac{1}{2} \left(\text{ModSim} + \text{DirSim} \right) $$
Baseline Models
- $\text{SVM/KNN}$: Uses SVM to classify force signals into phrases and KNN to predict force profiles from phrases.
- $\text{DMLP}_B$: Direct MLP mapping between force profiles and binary phrase vectors without a shared latent space.
- $\text{DMLP}_S$: Direct MLP mapping between force profiles and SBERT-embedded phrases without a shared latent space.
- $\text{DAE}_B$ (Ours): Dual autoencoder with binary phrase vectors.
- $\text{DAE}_S$ (Ours): Dual autoencoder with SBET embeddings.
Experiments
To evaluate the effectiveness of our cross-modality embedding framework, we conducted three main experiments:
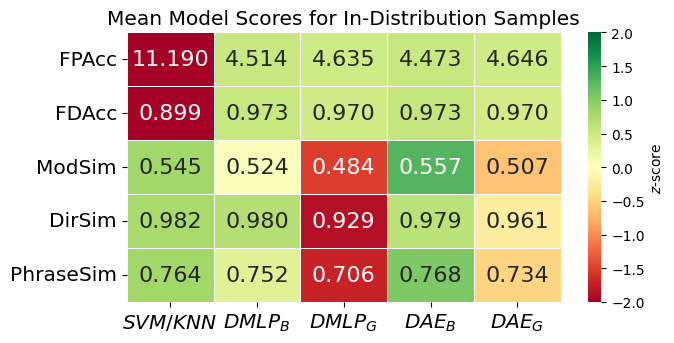
- In-Distribution Evaluation: The dataset was randomly split into 90% training and 10% testing sets. Models were trained and tested on the same distribution of force–phrase pairs and averaged across 30 independent seeds to reduce variability in the results.
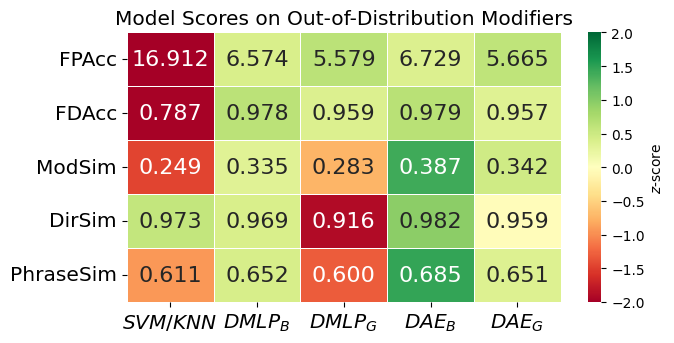
- Out-of-Distribution Modifiers: To test generalization, we systematically held out one modifier word (e.g., “slowly”) from the training set while keeping it in the test set. This experiment measured how well the models handled unseen adverbial variations in force descriptions.
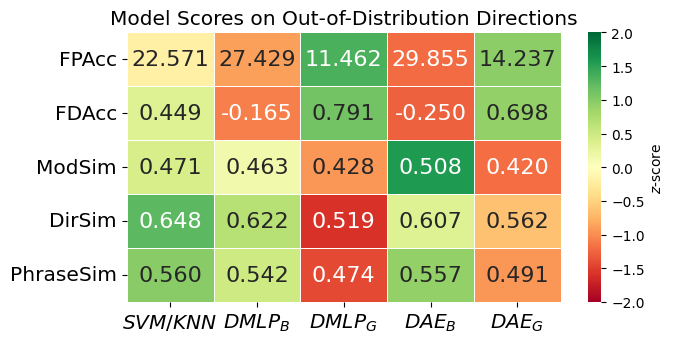
- Out-of-Distribution Directions: Similar to the modifier experiment, we excluded a single direction word (e.g., “up”) from training and evaluated the model’s ability to generalize to new directional inputs. This tested whether the models could infer force trajectories for previously unseen movement directions.
Overall Results
Our framework outperforms baseline models in both force-to-language and language-to-force translation, demonstrating the effectiveness of a shared latent space.
Analysis
Our results showed that the dual autoencoder (DAE) models significantly outperformed baseline approaches in both force-to-language and language-to-force translation. The DAE models achieved better performance than simpler SVM and MLP-based baselines, demonstrating that a shared latent space effectively captures the bidirectional relationship between physical force and linguistic descriptions.
Additionally, the models successfully generalized to unseen modifiers and directions, particularly when using SBERT embeddings, which improved force profile reconstruction. However, we observed a trade-off between force reconstruction accuracy and linguistic precision: the SBERT-based model (\( \text{DAE}_S \)) was better at estimating realistic force trajectories, while the binary phrase vector model (\( \text{DAE}_S \)) provided more precise textual descriptions.
These findings confirm that integrating force and language into a unified representation enhances natural human-robot communication, with different representation choices offering advantages depending on whether force accuracy or linguistic fidelity is prioritized.