Framework
Our framework consisted of a dual autoencoder model that was trained to encode inputs from both modalities into a shared latent space and decode them back to construct instances of either modality.
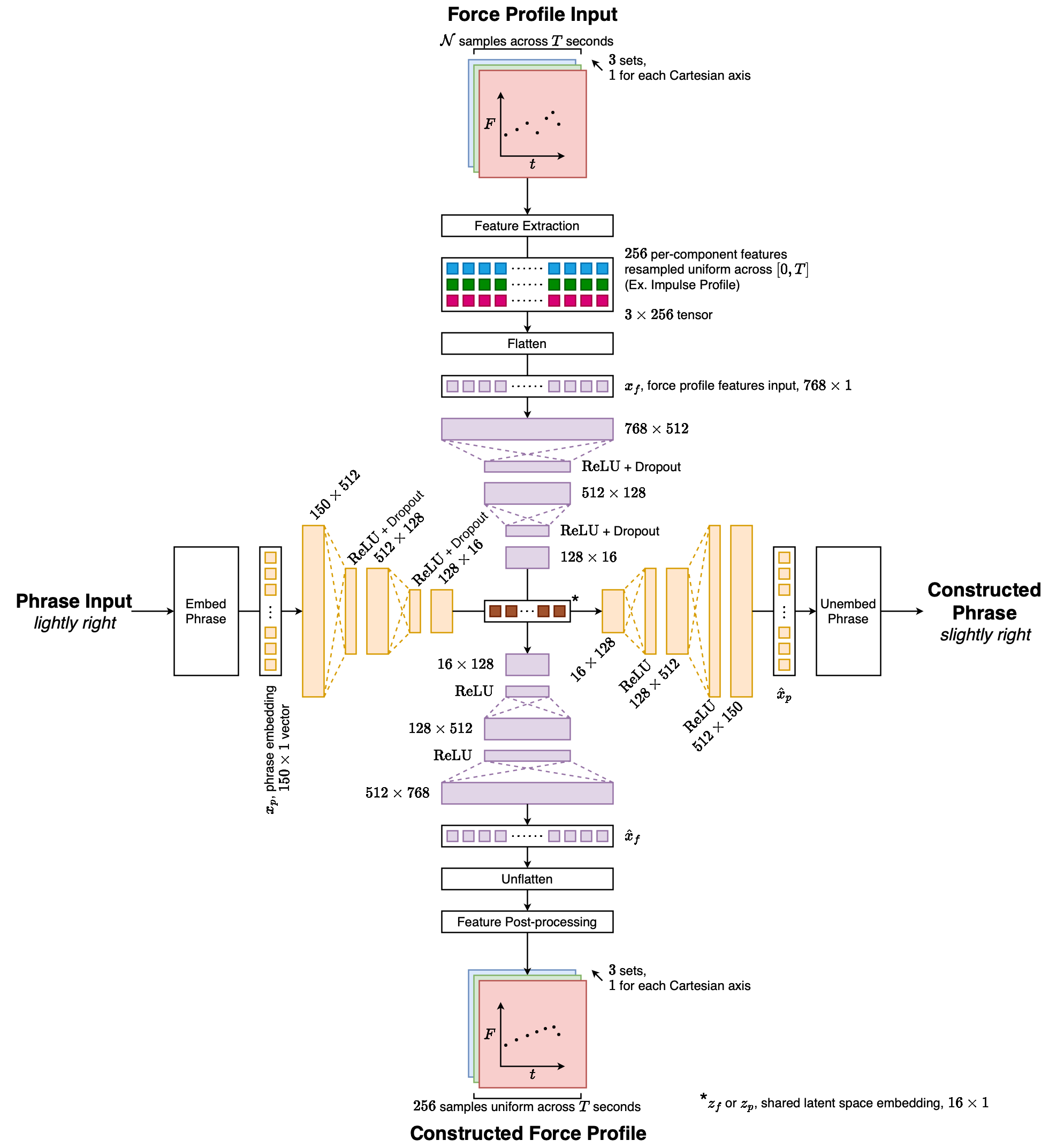
Architecture diagram of the cross-modality dual autoencoder that represents phrases as a concatenation of three 50×1 GloVe word embeddings. The phrase embedding input is then passed into the phrase autoencoder, which encodes it into the shared latent space. There the 16×1 embedding can take 2 paths: either be decoded back into a phrase or be translated into a force profile by using the force profile decoder. Force profile inputs are first preprocessed to extract meaningful features for the force profile autoencoder to digest. They are then encoded into the shared latent space. Like phrase inputs, they can either be decoded back into a force profile or be translated into a phrase by using the phrase decoder.
| Input Type | Flattened Force Profile Features | Binary Phrase Vector | SBERT Embedding Phrase Vector |
|---|---|---|---|
| Input Vector | 769×1 | 62×1 | 150×1 |
| Encoder Layer 1 | 768×512 | 62×512 | 769×512 |
| Encoder Activation 1 | ReLU + Dropout | ReLU + Dropout | ReLU + Dropout |
| Encoder Layer 2 | 512×128 | 512×128 | 512×128 |
| Encoder Activation 2 | ReLU + Dropout | ReLU + Dropout | ReLU + Dropout |
| Encoder Layer 3 | 128×16 | 128×16 | 128×16 |
| Latent Space Vector | 16×1 | 16×1 | 16×1 |
| Decoder Layer 1 | 16×128 | 16×128 | 16×128 |
| Decoder Activation 1 | ReLU | ReLU | ReLU |
| Decoder Layer 2 | 128×512 | 128×512 | 128×512 |
| Decoder Activation 2 | ReLU | ReLU | ReLU |
| Decoder Layer 3 | 512×769 | 512×62 | 512×150 |
| Output Vector | 768×1 | 62×1 | 768×1 |
Hyperparameters
Dropout chance: 10%
Number of training epochs: 1024
Adam learning rate: 0.001
Force profiles were augmented with per sample random noise residuals with mean 0 and variance 1