Cross-modality Force and Language Embeddings for Natural Human-Robot Communication
We present a framework that maps language and force into a shared latent space, enabling seamless translation between verbal commands and physical interactions. Using a dual autoencoder model trained on human data, our approach facilitates natural human-robot collaboration and lays the groundwork for multimodal communication in robotics.
Framework 🔗
Our framework consisted of a dual autoencoder model that was trained to encode inputs from both modalities into a shared latent space and decode them back to construct instances of either modality.
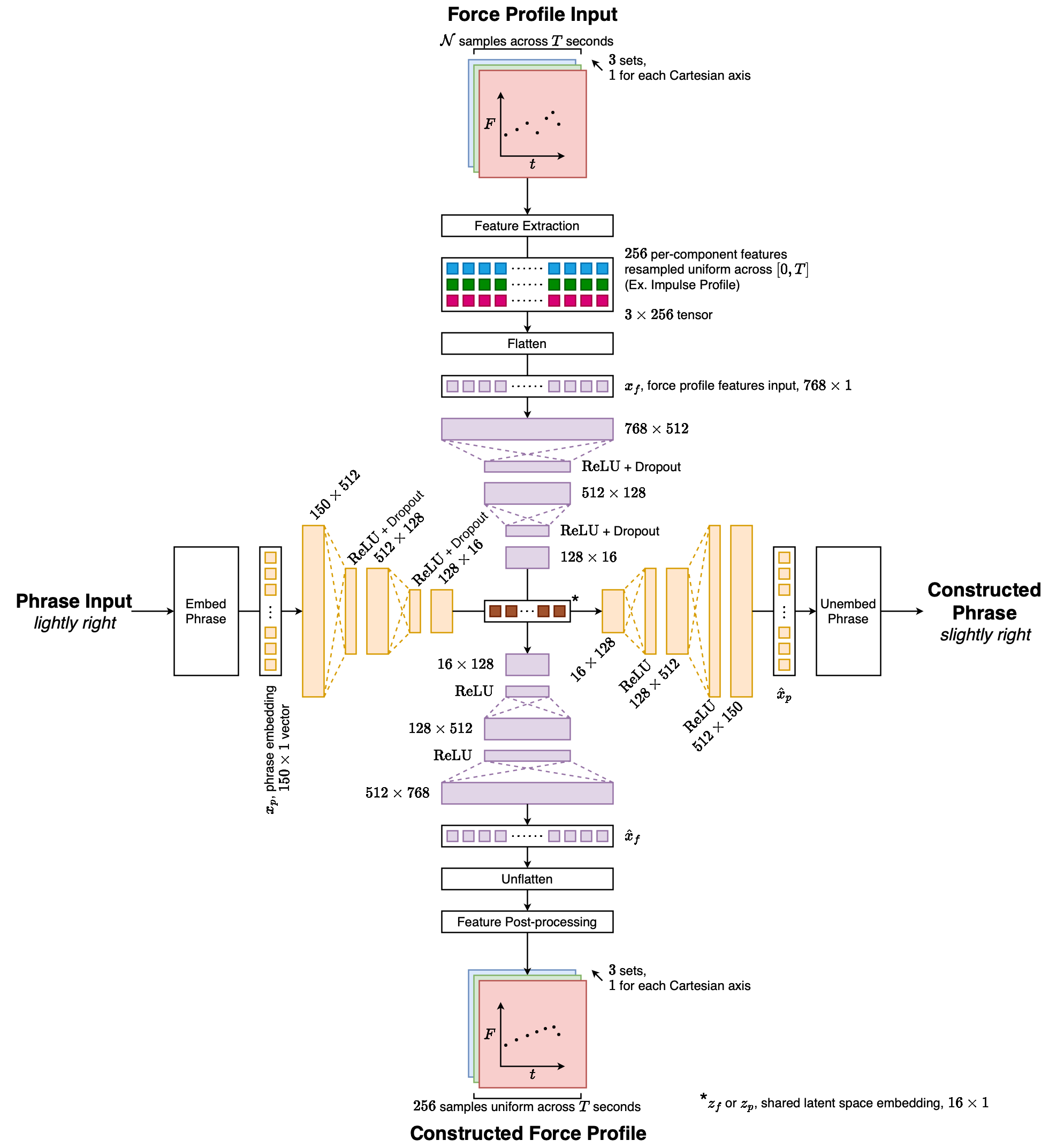
Architecture diagram of the cross-modality dual autoencoder that represents phrases as a concatenation of three 50×1 GloVe word embeddings. The phrase embedding input is then passed into the phrase autoencoder, which encodes it into the shared latent space. There the 16×1 embedding can take 2 paths: either be decoded back into a phrase or be translated into a force profile by using the force profile decoder. Force profile inputs are first preprocessed to extract meaningful features for the force profile autoencoder to digest. They are then encoded into the shared latent space. Like phrase inputs, they can either be decoded back into a force profile or be translated into a phrase by using the phrase decoder.
Therapy Sessions 🔗
We conducted an observational study of a physical therapist demonstrating various therapeutic techniques on a patient with neurological injuries at the Spaulding Rehabilitation Center, Cambridge, MA. The therapist’s use of both verbal and physical gestures to guide patients motivated us to develop a framework that could learn the relationship between the 2 modalities.
Data Collection 🔗
To train and evaluate the shared language-force embedding framework, we collected data from 10 participants interacting with a robot arm. Each participant underwent 2 procedures, Phrase-To-Force and Force-To-Phrase, each examining translation from one modality to the other.
Results 🔗
We evaluated 2 variations of our framework against 3 other baseline models. Our experiments were designed to assess the performance of our framework on language-force translation and generalization to unseen examples. It also tested the impact of the framework leveraging different phrase representations.
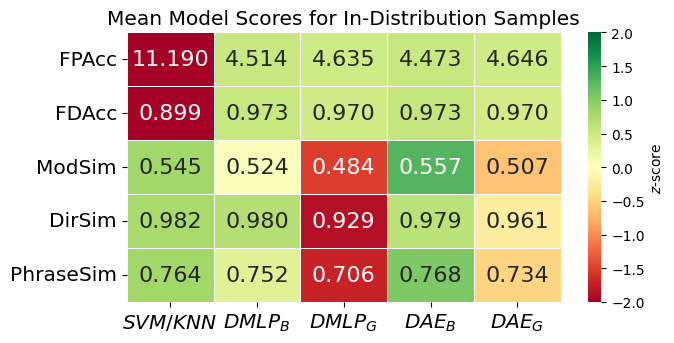
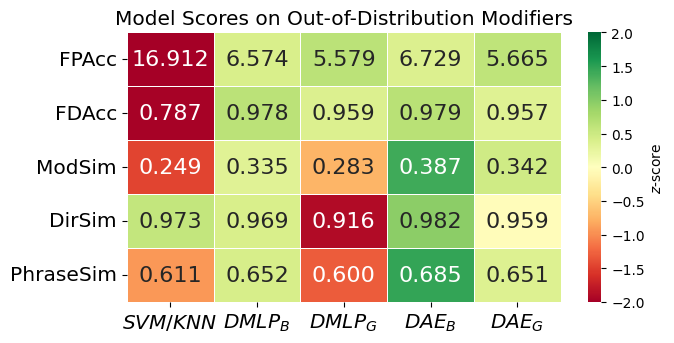
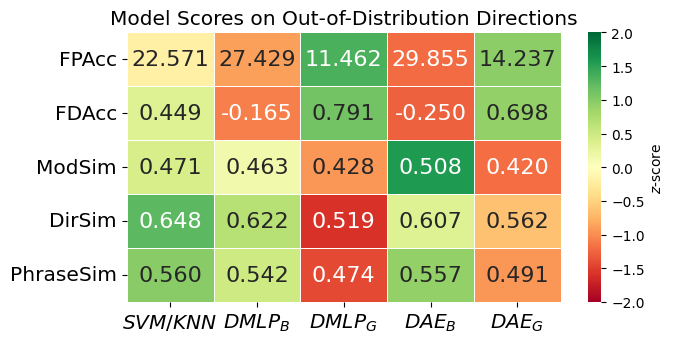
Our dual autoencoder models consistently outperformed the baselines across all core metrics. They also generalized well to unseen modifiers and directions, especially whiling using SBERT embeddings, which enhanced force profile accuracy. Meanwhile, binary-based embeddings offered more precise textual output. Overall, unifying force and language in a single representation enables more natural and robust human-robot interactions.
Code
Refer to the Shared Language-Force Embedding repository for the codebase of our framework and baseline models.